商品期货量化交易-TradingviewPine语言基础课程
 0
319
0
319
。 优宽上限制不是那么严苛,但是也建议遵循Trading View上的规范书写。例如这样虽然在优宽上不报错,不过不建议这样写。 * 虽然允许在本地块中进行函数调用, 它们的功能与在脚本的全局范围内的功能相同(比如input)。 * 条件结构中的局部块必须缩进四个空格或制表符。 * 在赋值判断时,所有分支表达式都不为真,也没有else分支,则返回na。
x = if close > open
close
runtime.log('x:',x)
- 条件结构和循坏结构都是可以根据你的交易逻辑互相嵌入的。
switch语句
switch可以来说是if语句的另外一种呈现形式。switch也可以用来赋值或者进行逻辑操作。一般来说switch语句之后的分支条件必须是互斥的。就是说各分支的条件不能同时成立。因为switch只能执行一个分支的本地代码块。
switch的每个分支都可以写一个本地代码块,这个本地代码块的最后一行即为返回值(它可以是一个值的元组)。如果没有任何分支被的本地代码块被执行,则返回na。
带有表达式的switch
switch结构中的表达式判断位置,可以写字符串、变量、表达式或函数调用。变量indic的值就为一个字符串,变量indic作为switch的表达式(可以是变量、函数调用、表达式),来确定执行switch中的哪个分支。如果变量func无法和switch中的任一个分支上的表达式匹配(即相等),则执行默认的分支代码块,会执行runtime.error(“error”)函数导致策略抛出异常停止。
indic = input('close', title="指标名称", tooltip="选择要使用的指标函数名称", options=['close', 'open', 'high', 'low', 'null'])
switch indic
'close' =>
runtime.log('收盘价:', close)
'open' =>
runtime.log('开盘价:', open)
'high' =>
runtime.log('最高价:', high)
'low' =>
runtime.log('最低价:', low)
=>
runtime.error('没有指标')
不带有表达式的switch
接下来我们看switch的另一种使用方式,即不带表达式的写法。
up = close > open
down = close < open
switch
up =>
runtime.log('涨')
down =>
runtime.log('跌')
测试代码例子就可以看到,switch会匹配执行分支条件上为真的本地代码块。一般来说switch语句之后的分支条件必须是互斥的。就是说例子中up和down不能同时为true。因为switch只能执行一个分支的本地代码块。除此之外还需要注意尽量不要把函数调用写在switch的分支中,函数无法在每个BAR上被调用可能引起一些数据计算的问题(除非如同「带有表达式的 switch」例子中,执行分支是确定的,在策略运行中是不会被更改的)。
请注意,在tradingview上,各个分支的返回值需要是一致的,比如统一的变量type类型(数字,字符,元组等),但是在优宽上没有明确的要求,可以根据需要设置需要的返回值,优宽实现了类型的兼容。
循环结构
虽然Pine语言中有很多内置函数可以帮助我们进行循环的计算,但是循环的存在是有充分理由的,因为即使在 Pine 语言中,它们在某些情况下也是必需的。这些情况通常包括:
- 数组(array)的操作。
- 回顾历史,使用只能 在当前柱上已知,例如,找出有多少过去的高点高于当前柱线的高点。由于当前柱线的高点仅在运行脚本的柱上已知,循环是必要的,可以回到过去并分析过去的柱线。
- 使用Pine语言的内置函数无法完成对过去BAR的计算的情况。
for语句
for语句使用非常简单。for语句之后跟随一个「计数」变量用于控制循环次数、引用其它值等,「计数」变量在循环开始之前被赋值为「初始计数」,然后根据「步长」设置递增,当「计数」变量大于「最终计数」时循环停止。for循环可以最终返回一个值(或者返回多个值,以[a, b, c]这样的形式),或者进行循环的操作。
for 起始计数 to 最终计数 by 步长 //优宽暂时不支持反向操作
语句 // 注释:语句里可以有break、continue
操作
x = for 起始计数 to 最终计数 by 步长
语句
返回值//循坏过后最终的值
下面举例示范下:
//操作
for i = 0 to 10
runtime.log("i:", i)
runtime.error("stop")
//赋值
ret = for i = 0 to 10
runtime.log("i:", i)
i // 如果这行不写,就返回空值,因为没有可返回的变量
runtime.log("ret:", ret)
runtime.error("stop")
在if语句中是可以插入break(跳出整个循环)这个循环和continue(跳过本次条件)。
for i = 0 to 10
runtime.log("i:", i)
if i == 3
break
for i = 0 to 10
runtime.log("i:", i)
if i == 3
continue
for…in 语句
for.in语句主要针对对象为数组,主要有以下两种形式:
for 数组元素 in 数组
语句 // 注释:语句里可以有break,continue
for [索引变量, 索引变量对应的数组元素] in 数组
语句 // 注释:语句里可以有break,continue
可以看到两种形式的主要差别就在于for关键字之后跟随的内容,一种是使用一个变量作为引用数组元素的变量。一种是使用一个包含索引变量,数组元素变量的元组的结构来引用[索引i, 元素ele]。其它的返回值规则,使用break、continue等规则和for循环一致。我们也通过一个简单的例子来说明使用。
testArray = array.from(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)
for ele in testArray
runtime.log("ele:", ele)
runtime.error("stop")
for [i, ele] in testArray
runtime.log("ele:", ele, ", i:", i)
runtime.error("stop")
while语句
while语句让循环部分的代码一直执行,直到while结构中的判断条件为假(false)。和if语句一致,while语句也可以进行赋值或者逻辑操作,while语句的基本结构为
while 判断条件
操作 // 注释:语句里可以有break,continue
返回值 = while 判断条件
语句 // 注释:语句里可以有break,continue
语句 // 注释:最后一条语句为返回值
while的其它规则和for循环类似,循环体本地代码块最后一行是返回值,可以返回多个值。当「循环条件」为真时执行循环,条件为假时停止循环。循环体中也可以使用break、continue语句。
i = 0
while i <= 10
runtime.log('i',i)
i += 1
runtime.error("stop")
x = while i <= 10
runtime.log('i',i)
i += 1
i//循环体结束后最后的值
runtime.log('x:',x)
runtime.error("stop")
Pine语言最后一块语法拼图已经讲解完毕,我们下节课再见。
(九):时间序列
你做过交易吗,连续高长时间的紧盯着一块屏幕,密切的观察指标的变化,不断地在衡量交易的规律和趋势,决定交易操作,执行并继续观察交易结果,不断地调仓补仓平仓,直至最后交易时间段结束,还需要你进行更为深刻的自身,复盘总结今日某一瞬间的得失。这就是一个交易人,与市场,与大盘,与庄家,与自己的战斗。每天都在不断上演。交易可以量化吗?有时候你会怀疑,怎样利用语言去模拟一个金融市场,无数伴随着每豪每秒的纷繁信号,眼花缭乱的涨跌趋势,怎样去抓取其中的规律,预测未来?这就需要我们深入了解Pine语言对于交易逻辑的处理–时间序列和模型执行。
这两部分的内容其实应该在Pine语言,入门的时候为大家讲解,可是理解起来确实有些困难。因此在为大家讲述完,Pine语言基本语法结构的基础上编写简单的代码,为大家进行更好的展示。
时间序列
首先,我们讲解时间序列,在类型系统中我们粗略的介绍过。时间序列并不是一种数据类型或者格式,时间序列是PINE语言中一种基本结构的概念。用来储存时间上连续变动的值,每个值都对应一个时间点。时间序列这种概念的结构很适合应用于处理、记录随时间变化的一系列数据。
我们知道Pine脚本是基于图表的,图表中展示的最基本的内容就是K线图。时间序列其中每个值都与一个K线Bar的时间戳关联。PINE语言这样设计时间序列,可以在策略代码中很轻松地计算收盘价的累计值,而且不需要使用for之类的循环结构,只用使用PINE语言的内置函数ta.cum()。下面我们举例进行一下解释:
这段代码的意思是,在一个策略周期内,我们设置两个变量,第一个变量v1,赋值为整数1,第二个变量v2是伴随策略周期累加的v1值,然后我们使用plot函数将v1,v2和k线bar的索引,这个内置变量bar.index在图表中展示出来。
v1 = 1
v2 = ta.cum(v1)
plot(v1, title="固定v1")
plot(v2, title="累计v1")
plot(bar_index+1, title="bar序列")
有很多类似ta.cum这样的内置函数可以直接处理时间序列上的数据,例如ta.cum就是把传入的变量在每个K线Bar上对应的值累加起来,接下来我们使用一个图表来方便理解。
| 策略运行时间段 | 内置变量bar_index | 内置变量bar_index + 1 | 固定v1 | 累计v2 |
|---|---|---|---|---|
| 策略运行第一根K线Bar: 0 到 1 分钟 | 0 | 1 | 1 | 1 |
| 策略运行第一根K线Bar: 1 到 2 分钟 | 1 | 2 | 1 | 2 |
| 策略运行第一根K线Bar: 2 到 3 分钟 | 2 | 3 | 1 | 3 |
| 策略运行第一根K线Bar: 3 到 4 分钟 | 3 | 4 | 1 | 4 |
| 策略运行第一根K线Bar: 4 到 5 分钟 | 4 | 5 | 1 | 5 |
可以看到,他们都是时间序列结构,在每根Bar上都有对应的数据。

因为固定v1这个变量在每一根Bar上都是1,ta.cum(v1)函数在第一根K线Bar上执行时由于只有第一根Bar,所以计算结果为1,赋值给变量累计v2。
当ta.cum(v1)在第二根K线Bar上执行时,已经有2根K线Bar了(第一根对应的内置变量bar.index是0,第二根对应的内置变量bar.index是1),所以计算结果为2,赋值给变量v2,以此类推。实际上可以观察到v2就是图表中K线Bar的数量,由于K线的索引bar.index是从0开始递增,那么bar.index + 1实际上也就是K线Bar的数量。观察图表也可以看到v2和bar.index确实是重合的。
需要注意的是,虽然时间序列很容易让人想起「数组」这种数据结构,虽然PINE语言也有数组类型。但是它们和时间序列是完全不同的概念。
在时间序列上调用函数的结果也会在时间序列上留下痕迹,同样可以使用[]历史操作符引用之前的值。例如,计算最后10根K线BAR中的最高价的最大值时(不包括当前的K线BAR)。我们可以写为 ta.highest(close, 10)[1],同样也可以写成 ta.highest(close[1], 10)。两者是等价的。
可以用以下代码验证:
strategy("test pine", "test", true)
a = ta.highest(close, 10)[1]
b = ta.highest(close[1], 10)
runtime.log("a",a)
runtime.log("b",b)
PINE语言这样设计时间序列,可以在策略代码中很轻松地进行时间逻辑的运算。但是需要了解其具体的运行机制,我们可以进行一个展示。
pricecum1 = ta.cum(close)
pricecum2 = close // pricecum2 = close+close[1]+close[2]
for i=1 to 2
pricecum2 += close[i]
i += 1
runtime.log("pricecum1:", pricecum1)
runtime.log("pricecum2:", pricecum2)
策略是从09:00准时开始的,用一分钟为K线周期,我们进行五分钟的策略回测(09:00至09:05),因为最后的K线是09:05还没有更新完,所以09:05的数据是不显示的,只能展示四个值(0到1,1到2,2到3,3到4,四个时间段)。在回测日志中,我们可以观察到pricecum1使用ta.cum函数,从策略起始处(0到1)就开始计算累加值,直到(0到4),所以计算了四段k线的累加值。而pricecum2,以三分钟的k线累加值为一个轮回进行循环计算,因为在0到1和1到2处,没有前两个值,即close[1]和close[2],所以第一分钟,和第二分钟的pricecum2为空值,到第三分钟时,pricucum2 = close + close[1] + close[2], 三个值都是实值了,可以进行计算,并且和pricecum1相等。因为pricecum2以3为周期,所以pricecum1和pricecum2在第四分钟两者时不相等的,这个时候pricecum1计算的是0到1,1到2,2到3,3到4,四个时间段的收盘价累加值;而pricecum2计算的是1到2,2到3,3到4,三个时间段的收盘价累加值。这是一个时间序列的例子,大家可以回味下。
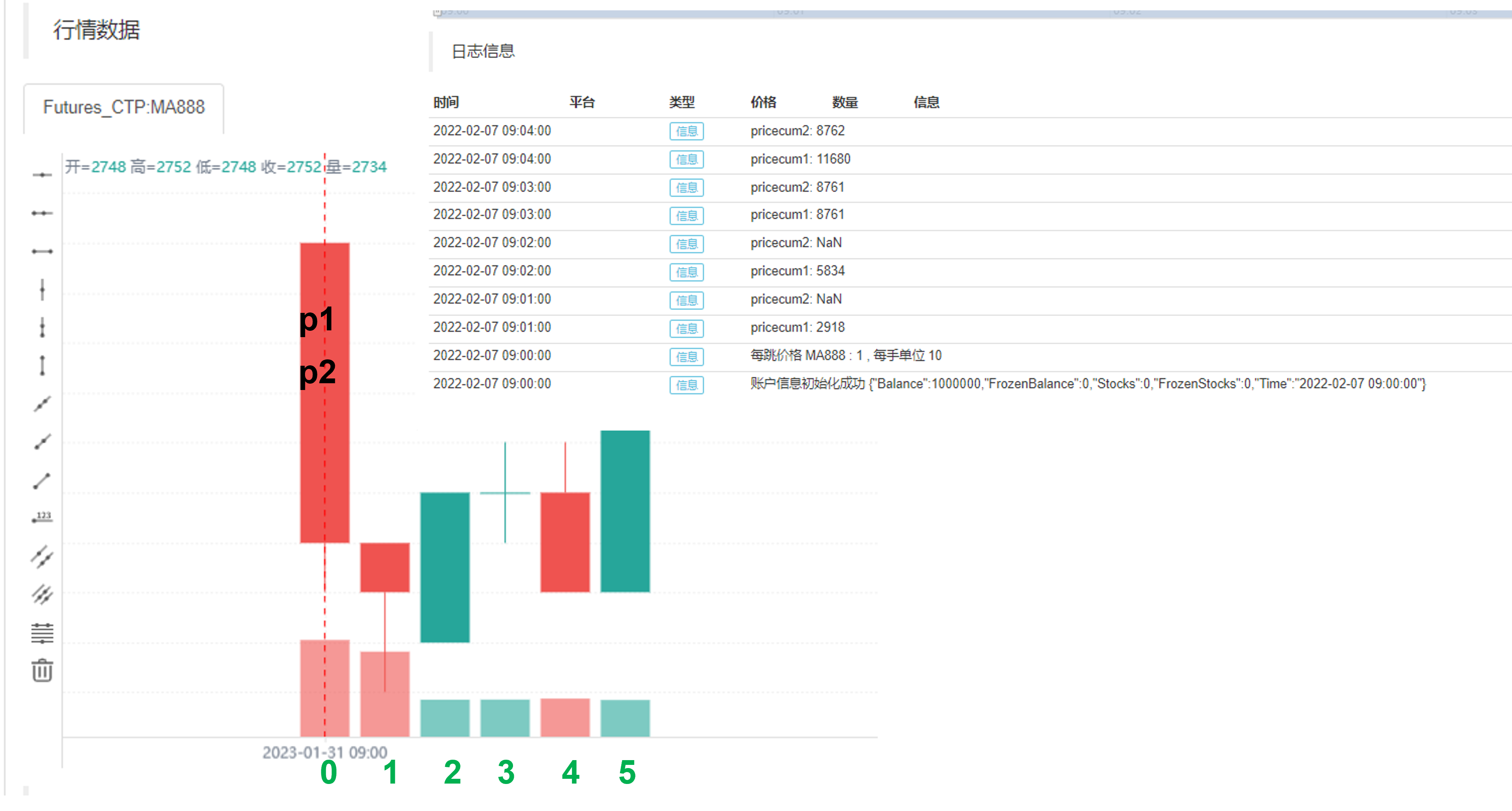
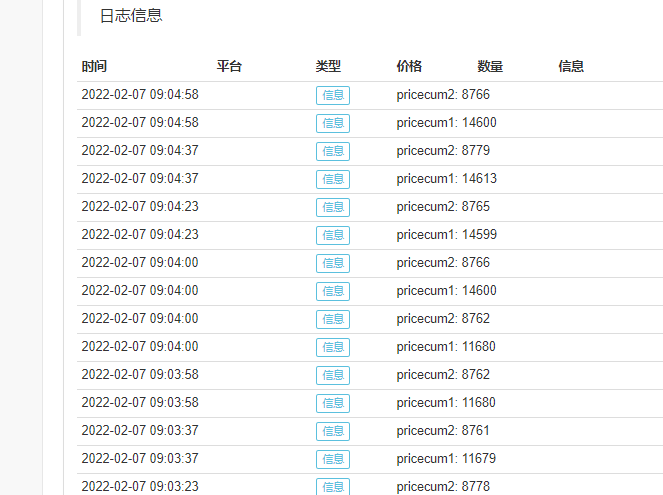
我们可以看到策略从初始值实时更新的时候,是不会使用过去的历史bar,因此如果在策略中你使用了循环语句,去利用过去的指标去判断交易的逻辑。在策略开始的时候,你需要等待循环逻辑走完,才能进行交易的处理。第二点请注意,这里我们选择的是收盘价模型,如果我们这里选择的是实时价模型,进行策略的运行,日志的结果将会是这样。这两者的区别涉及到模型执行机制,我们下节课为大家继续讲解。
# (十):模型执行
今天我们继续学习Pine语言的模型执行。在了解Pine语言时间序列基础上,你的交易逻辑是想基于实时价模型或者收盘价模型?收盘价模型对于趋势策略比较友好,而实时价模型更多的适用于震荡策略,当然这并没有固定的限制。但是如果你想更加准确的用Pine语言模拟你的交易思想,那么这部分内容你一定不要错过。
模型执行
在入门学习Pine语言时,是非常有必要了解Pine语言脚本程序执行过程等相关概念的。Pine语言策略是基于图表运行的,可以理解为Pine语言策略为一系列的计算和操作,在图表上以时间序列的先后顺序从图表已经加载的最早数据开始执行。图表中加载的Bar有两个部分,策略开始前的历史Bar和策略开始后的实时Bar。
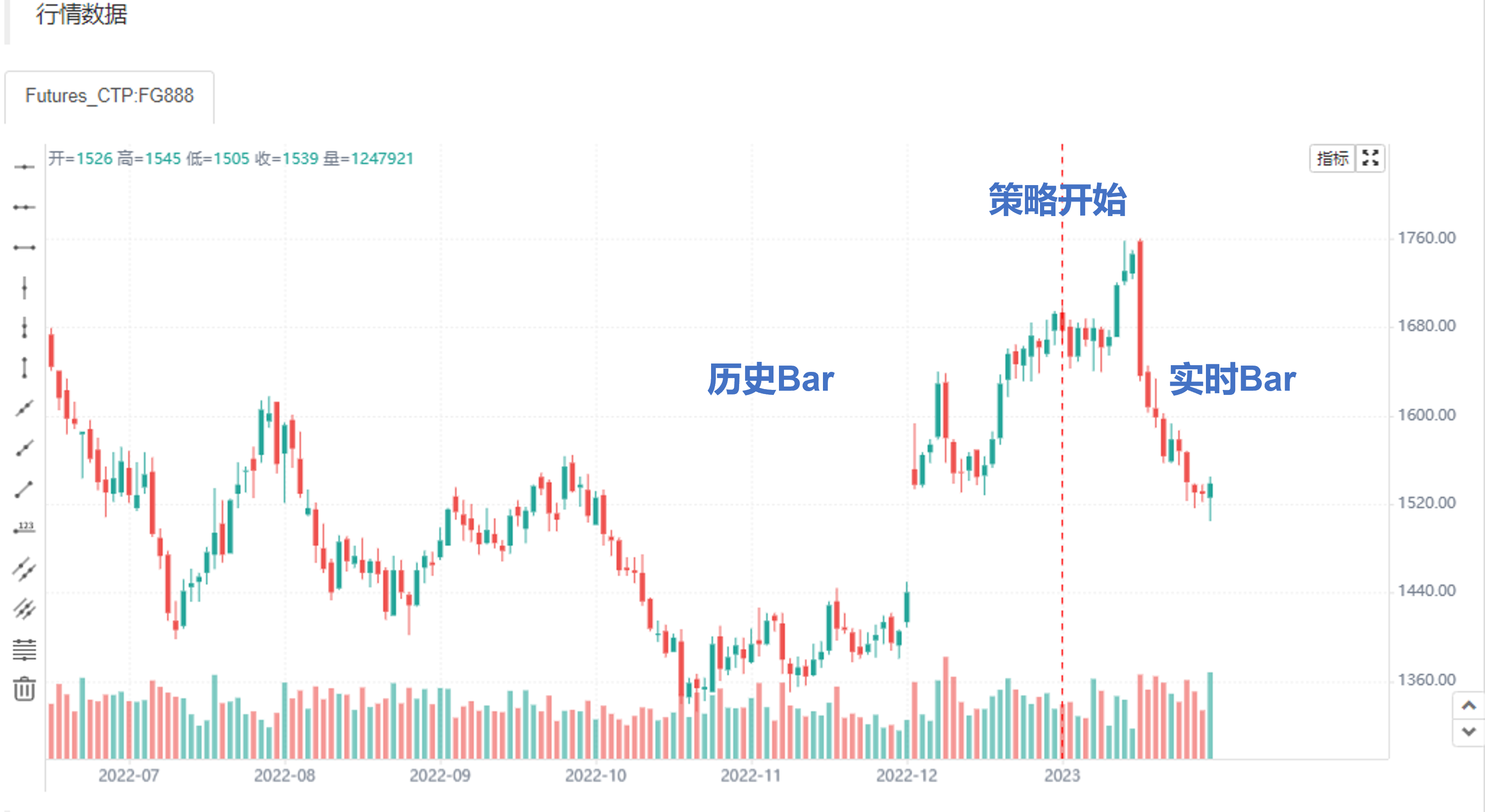
图表中历史Bar初始加载的数据量是有限的。实盘时通常这个数据量上限是基于交易所接口返回的最大数据量决定,回测时数据量上限是基于回测系统数据源提供的数据决定。
收盘价模型 vs. 实时价模型
根据策略的设置不同,策略的模型执行方式也不同,分为收盘价模型和实时价模型。
收盘价模型 策略代码执行时,当前K线Bar的周期完全执行完成,K线闭合时即K线周期已经走完。此时执行一遍Pine策略逻辑,触发的交易信号将在下一根K线Bar开始时执行。
实时价模型 策略代码执行时,当前K线Bar不论是否闭合,每次行情变动就执行一遍Pine策略逻辑,触发的交易信号立即执行。
当Pine语言策略在图表上从左至右执行时,图表上的K线Bar是分为历史Bar和实时Bar的:
历史Bar 策略设置为「实盘价模型」开始执行时,图表上除了最右侧的那一根K线Bar之外所有K线Bar都是历史Bar。策略逻辑在每根历史Bar上仅执行一次。策略设置为「收盘价模型」开始执行时,图表上所有Bar都是历史Bar。策略逻辑在每根历史Bar上仅执行一次。 基于历史Bar的计算:策略代码在历史Bar收盘状态下执行一次,然后策略代码继续在下一个历史Bar执行,直到所有历史Bar都执行一次。
实时Bar 当策略执行到最右边的最后一根K线Bar上时,该Bar为实时Bar。当实时Bar闭合之后,这根Bar就变成了一个经过的实时Bar(变成了历史Bar)。图表最右侧会产生新的实时Bar。策略设置为「实时价模型」开始执行时,在实时Bar上每次行情变动都会执行一次策略逻辑。 策略设置为「收盘价模型」开始执行时,图表上不显示实时Bar。如果设置策略为「收盘价模型」图表不显示实时Bar,策略代码只在当前Bar收盘时执行一次。
如果设置策略为「实盘价模型」在实时Bar上的计算和历史Bar就完全不同了。例如内置变量high、low、close在历史Bar上是确定的,在实时Bar上可能每次行情变动时这些值是会发生变化的。所以基于这些值计算的指标等数据也是会实时变动的。在实时Bar上open是不变的,close始终代表当前最新价格,high和low始终代表自当前实时Bar开始以来达到的最高点和最低点。这些内置变量代表实时Bar最后一次更新时的最终值。
策略代码在历史Bar收盘状态下执行一次,然后策略代码继续在下一个历史Bar执行,直到所有历史Bar都执行一次。如果设置策略为「实盘价模型」在实时Bar上的计算和历史Bar就完全不同了,在实盘Bar上每次行情变动都会执行一次策略代码。
下面我们来举例说明下:
if open > close [1]
runtime.log("涨")
if open < close [1]
runtime.log("跌")
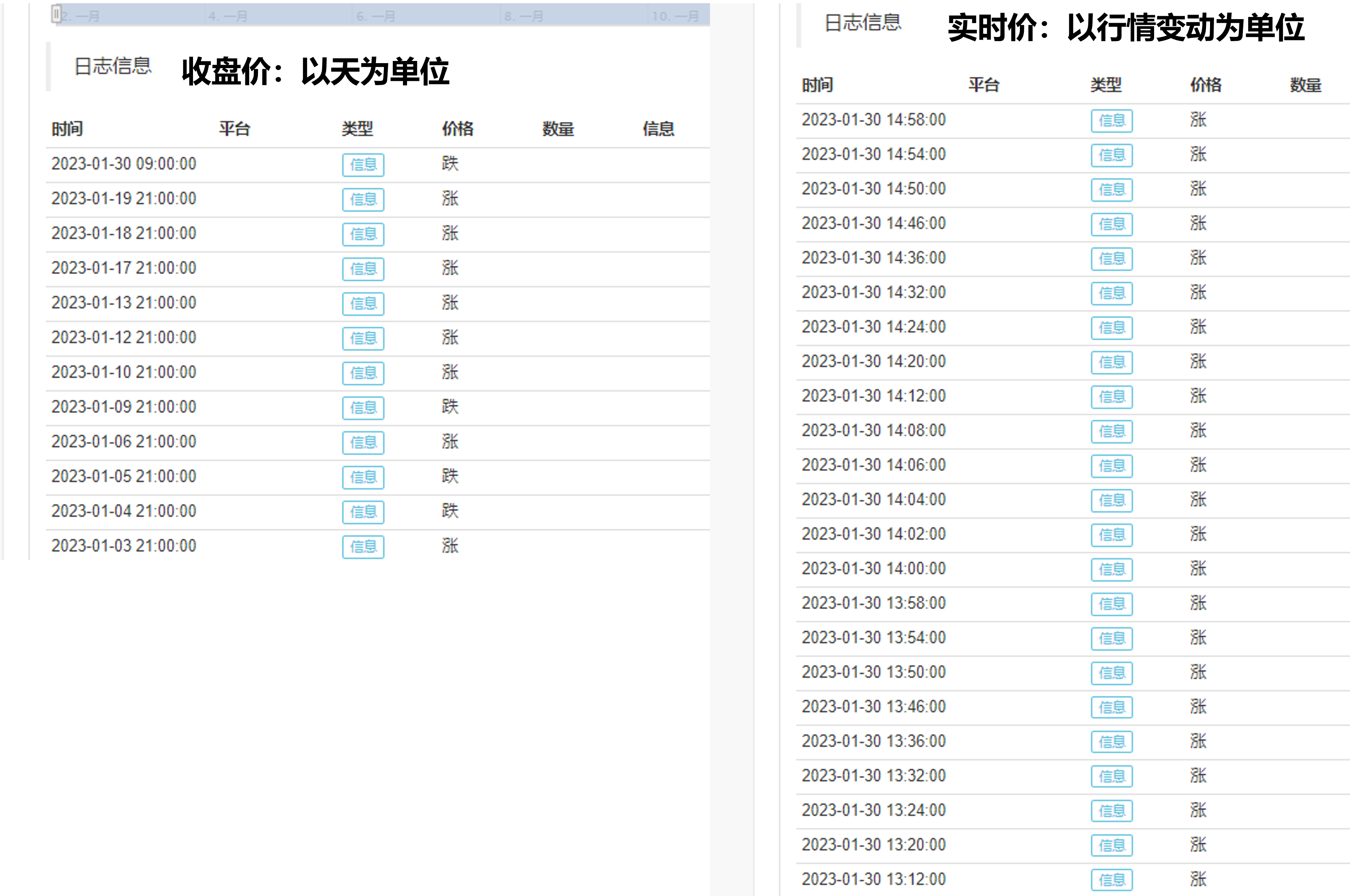
本策略以天为周期,打印出每个策略周期的涨跌值。当用收盘价为模型的时候,打印操作是在历史Bar收盘状态下执行的,所以以天为单位进行打印;而用实时价为模型,打印操作是在实时Bar上进行,每次行情变动都会打印一次。
实时Bar上执行策略时的回滚机制
在实时Bar执行时,策略的每次新迭代执行前重置用户定义的变量称为回滚。我们来用声明变量var和varip理解回滚机制,其中声明变量应该在赋值运算符处讲解,但是在不了解时间序列和模型执行的基础上,对于大家理解起来比较困难,因此放在这里讲解,并以此用来了解策略的回滚机制。
声明模式: 其实变量在命名的时候,在声明变量时最先写的就是「声明模式」,变量的声明模式有三种即: 1、使用关键字var。 2、使用关键字varip。 3、什么都不写。
var var 是用于分配和一次性初始化变量的关键字。通常,不包含关键字var的变量赋值语法会导致每次更新数据时都会覆盖变量的值。 与此相反,当使用关键字var分配变量时,尽管数据更新,它们仍可以“保持状态”。
varip varip(var intrabar persist)是用于分配和一次性初始化变量的关键词。它与var关键词相似,但是使用varip声明的变量在实时K线更新之间保留其值。
其实说起来解释还是比较晦涩,我们举例示范下。
strategy(overlay=true)
var i = 0
varip ii = 0
plotchar(true, title = 'i', char=str.tostring(i), location=location.abovebar, color=color.aqua)
plotchar(true, title = 'ii', char=str.tostring(ii), location=location.belowbar, color= color.blue)
i := i+1
ii := ii+1
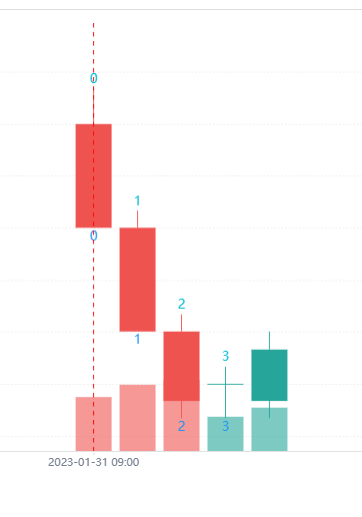
- 收盘价模型
我们看到在收盘价模型中, var 和 varip 没有区别,只是在策略周期更新时进行一次更新。由于收盘价模型是每根K线BAR走完时才执行一次策略逻辑。所以在收盘价模型时,历史K线阶段和实时K线阶段,var、varip声明的变量在以上例子中递增表现完全一致,都是每根K线BAR递增1。
- 实时价模型
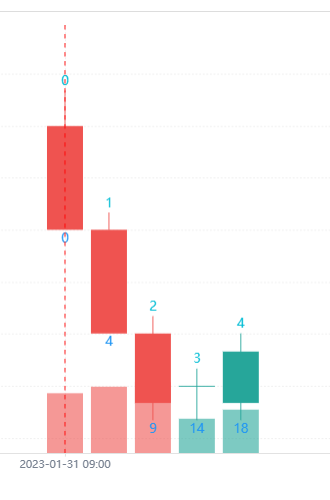
当在实时价模型,历史K线阶段时var、varip声明的变量i、ii在策略代码每轮执行时都会执行递增操作。所以可以看到回测结果K线BAR上显示的数字逐个都是递增1的。当历史K线阶段结束,开始实时K线阶段。var、varip声明的变量则开始发生不同的变化。因为是实时价模型,在一根K线BAR内每次价格变动都会执行一遍策略代码,i := i + 1和ii := ii + 1都会执行一次。区别是ii每次都修改。i虽然每次也修改,但是下一轮执行策略逻辑时会恢复之前的值,就是回滚,直到当前K线BAR走完才更新确定i的值(即下一轮执行策略逻辑时不再恢复之前的值)。所以可以看到变量i依然是每根BAR增加1。但是变量ii每根BAR就累加了好几次。
转变执行方式为实时价模型,其实策略更新就是跟随者tick的数据,进行策略逻辑的运行。在收盘价模型里,我们策略的更新,是上一个周期的一整个k线bar。而在实时价模型,伴随每次行情变动进行策略的运行,其实就是对比交易所返回的tick数据。这里我们选择模拟级tick,就是每分钟根据k线图模拟四个左右的tick数据。回到图表里,我们看到不带有关键字的变量每次都是计算加1,然后在下一次tick数据返回时,返回到原来的值。带有关键字var在每个tick周期内,虽然每次都计算,但是在一个策略周期内,都会保留原有的值;直到下一次策略周期的更新。而带有关键字varip的变量的变动是伴随着tick周期的,每次tick变动,都会进行计算和保留。
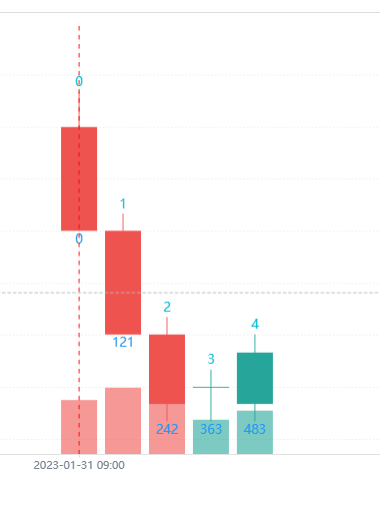
在实时价模型中,有模拟级tick和实盘级tick的返回机制。
模拟级tick: 一分钟四个模拟tick,所以每分钟varip增加4个左右。
实盘级tick: 根据交易所反馈的信息,针对于螺纹钢品种(其他品种可能不一样),每秒两个tick,所以每分钟varip增加120个。
总体来说,这部分比较困难。因为理解起来比较晦涩,所以需要简单的代码例子进行详细的说明和解释。这部分内容需要在较好的理解“时间序列”概念上,理解策略背后运行的机制–模型执行。了解收盘价模型和实时价模型的区别,通过var和varip理解实时价模型背后的回滚机制。只有在此基础上,才能对策略模型的原理有一个清楚的理解。当然,这也对理解“偷价”和“未来函数”,这些策略背后的陷阱有一个清楚的认识。
(十一):画图(1)
大家好,今天我们来学习Pine语言的画图功能。Pine语言是一门基于图表的语言,而在期货交易中,我们做的最多的事情就是看盘。众所周知,看盘是一件很累的事情,K线的不断涨跌彷佛牵动我们的每一刻神经。因此,如果能使用Pine语言,根据我们的交易理解,对我们的K线图进行私人优化,对指标进行更好的呈现,帮助我们快速进行决策的判断,这就是程序化交易的方便之处。在前面的课程中,我们使用了一些基本的画图函数,但是对于画图的参数我们并没有详细的解释。Pine语言具有丰富的图表功能,今天我们将使用代码范例为大家一一呈现。
plot
首先,我们学习最基本的plot函数,它的描述也很朴素:将一系列的数据在图表中进行展示。
strategy(overlay=true)
plot(series, title, color, linewidth, style, trackprice, histbase, offset, join, editable, show_last, display)
它里面有很多参数,我将挑些重点的为大家讲述下:
overlay (const bool) 优宽平台扩展的参数,用于设置当前函数在主图(设置true)或者副图(设置false)上画图显示,默认值为false。
series (series int/float) 要绘制的数据系列。 必要参数。
title (const string) 绘图标题。
color (series color) 绘图的颜色。您可以使用如’color = red’或’color =#ff001a’的常量。颜色的使用也可以用表达式,例如下例中这里的颜色使用是一个一个三元表达式,在抽盘价大于开盘价的时候,使用的是绿色,否则使用红色。三元表达式的使用很灵活,添加不同字符或者图形都可以根据你的需要进行设置。
style (plot_style) plot类型。可能的值有:plot.style_line、plot.style_stepline、plot.style_stepline_diamond、plot.style_histogram、plot.style_cross、plot.style_area、plot.style_columns、plot.style_circles、plot.style_linebr、plot.style_areabr。默认值为plot.style_line。在下一部分,将为大家一一进行展示。
linewidth (input int) 绘制线的宽度。默认值为1。它不适用于每种样式。
trackprice (input bool) 如果为true,则水平价格线将显示在最后一个指标值的水平。默认为false。
histbase (input int/float) 以plot.style_histogram,plot.style_columns或plot.style_area样式绘制图时,用作参考水平的价格值。默认值为0.0。
offset (series int) 在k线特定数量上向左或向右移动绘图。 默认值为0。
join (input bool) 如果为true,则绘图点将与线连接,仅适用于plot.style_cross和plot.style_circles样式。 默认值为false。
editable (const bool) 如果为true,则绘图样式可在格式对话框中编辑。 默认值为true。
show_last (input int) 如已设置,则定义在图表上绘制的k线数(从最后k线返回过去)。
display (plot_display) 控制显示绘图的位置。可能的值为:display.none、display.all。预设值为display.all。
大家可以感觉到Pine语言画图的参数很灵活,可以根据你的需要进行设置。下面我就plot.style中的不同形状为大家展示下。
plot.style
plot.style_line ‘Line’直线样式的命名常量,用作plot函数中style参数的参数。
plot.style_linebr ‘Line With Breaks’样式的命名常量,用作plot函数中style参数的参数。类似于plot.style_line,除了数据中的空白没有被填充。
plot.style_histogram ‘Histogram’柱状图样式的命名常量,用作plot函数中style参数的参数。在这里可以为大家展示刚才plot中histbase参数的用法。我们看到当histbase设置为2000时。图像由下所示。
plot(close, title='Title', color=color.new(#00ffaa, 70), linewidth=5, style=plot.style_histogram,histbase=2400)
plot.style_columns ‘Columns’ 样式的命名常量,和histgram区别不大。
plot.style_circles ‘Circles’ 样式的命名常量,用作plot函数中的style参数的参数。
plot.style_area ‘Area’样式的命名常量,用作plot函数中style参数的参数。
plot.style_areabr ‘Area With Breaks’样式的命名常量,用作plot函数中style参数的参数。类似于plot.style_area,除了数据中的空白没有被填充。
plot(close> open ? close : na , title='Title', color=color.new(#00ffaa, 70), linewidth=2, style=plot.style_area)
plot(close> open ? close : na , title='Title', color=color.new(#00ffaa, 70), linewidth=2, style=plot.style_areabr)
plot.style_cross ‘Cross’ 乘号样式的命名常量,用作plot函数中style参数的参数。
plot.style_stepline ‘Step Line’样式的命名常量,用作plot函数中style参数的参数。
fill
使用提供的颜色填充两个绘图或hline之间的背景。本例中使用fill画图画出了close和open之间的差距。
fill(plot1, plot2, color, title, editable, show_last, fillgaps, display)
p1 = plot(open)
p2 = plot(close)
fill(p1, p2, color=color.new(color.green, 90))
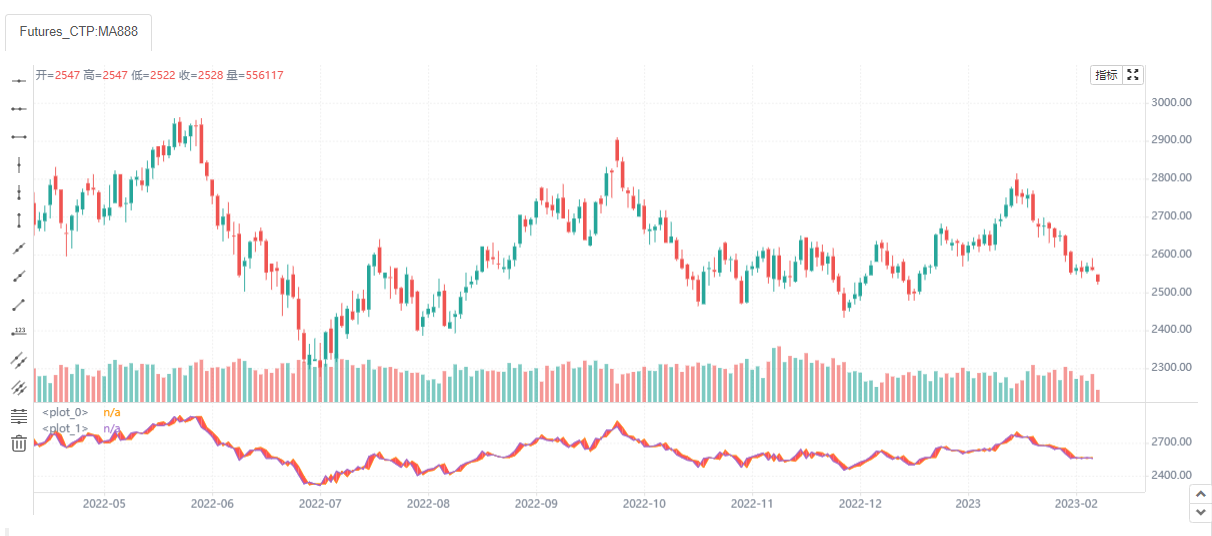
hline
在给定的固定价格水平上呈现水平线。其中参数linestyle (hline_style) 渲染线的样式。 可能的值有:solid(实线),dashed(虚线),dotted(点)。 注意,这里的hline是固定的,不能设置为随着策略周期的变化而变化。
strategy(overlay=true)
hline(2500, linestyle = hline.style_solid)
hline(3000, linestyle = hline.style_dashed)
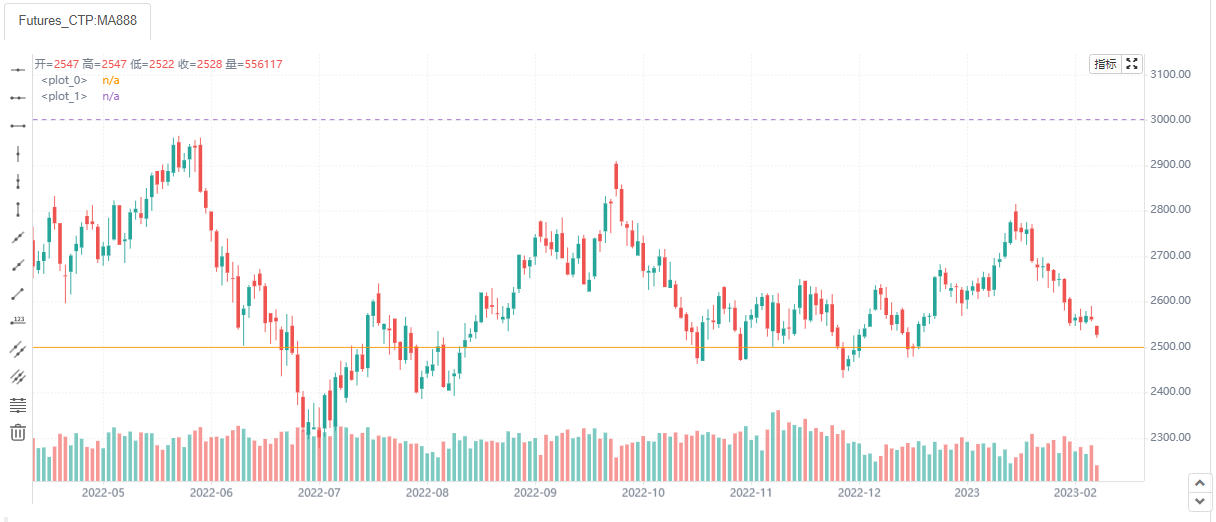
bgcolor
设置背景颜色,可以根据你的交易理念设置不同的背景颜色。
bgcolor(color, offset, editable, show_last, title, display, overlay)
// bgcolor example
bgcolor(close < open ? color.new(color.red,70) : color.new(color.green, 70))
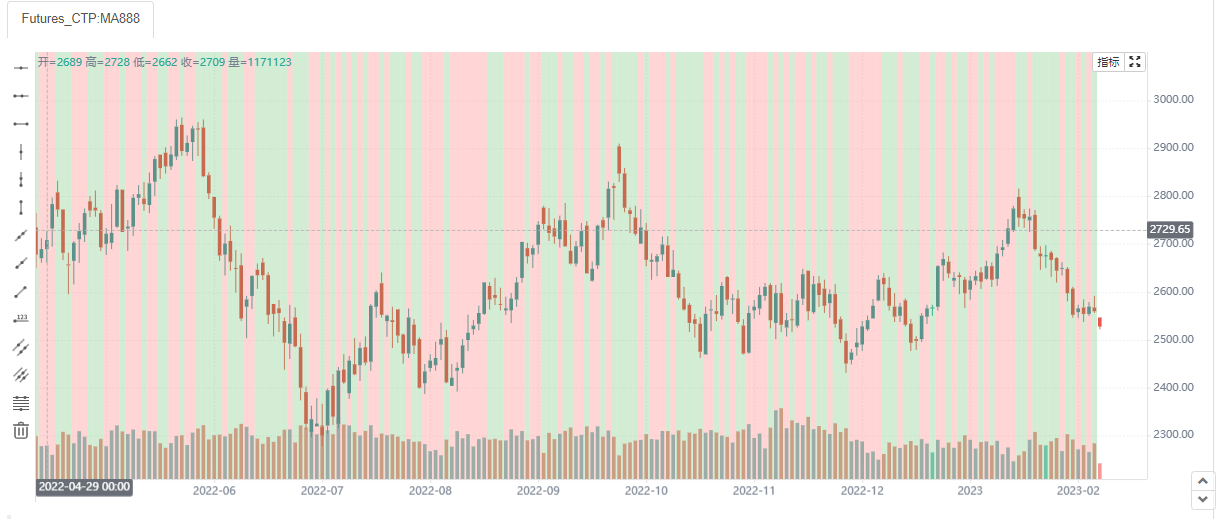
barcolor
设置K线颜色。在国际上,默认绿色代表的上涨,红色是下跌;而在中国,恰好相反。在优宽平台,k线使用的是国际标准,如果想进行更改,使用barcolor函数就可以。
barcolor(close < open ? color.black : color.white)
本节课的内容讲授结束,下节课我们将继续为大家讲解Pine语言画图的其他功能。
今天编写了Pine语言画图课程教案第一部分。Pine语言是一门基于图表的语言,而在期货交易中,交易者做的最多的事情就是看盘。看盘是一件很累的事情。因此,如果能使用Pine语言,根据交易理解,对K线图进行私人优化,对指标进行更好的呈现,帮助快速进行决策的判断,可以更加展示出Pine语言的优秀之处。画图部分内容比较多,需要大量的画图例子进行呈现,因此将画图部分讲解分为两个部分,第一部分讲解Pine语言plot函数及其重要的内置参数,ploy.style图表形状,以及其它画图函数fill,hline等,辅以代码和图像帮助学员进行更好的了解和使用。
(十二):画图(2)
大家好,今天我们继续来学习画图函数。在本节课的最后,我将利用画图函数打造一个简易的指标参考系统,帮助交易者在实盘交易中,及时检阅出市场信号,进而迅速进行交易操作,这对于半程序化交易者十分友好。
plotshape
首先我们学习plotshape函数,plotshape函数在图表上绘制可视形状。它的基本语法结构为:
plotshape(series, title, style, location, color, offset, text, textcolor, editable, size, show_last, display)
其重要的内置参数如下所示,基本上伴随策略周期变化的参数,都可以使用三元表达式,根据你的交易逻辑,在图中进行不同的展示:
- series (series bool) 作为形状绘制的一系列数据 。 除了交易指标外,这里也可以添加交易指标布尔值的形式(只显示布尔值判断为真的指标)。
data = close >= open
plotshape(data, style=shape.xcross)
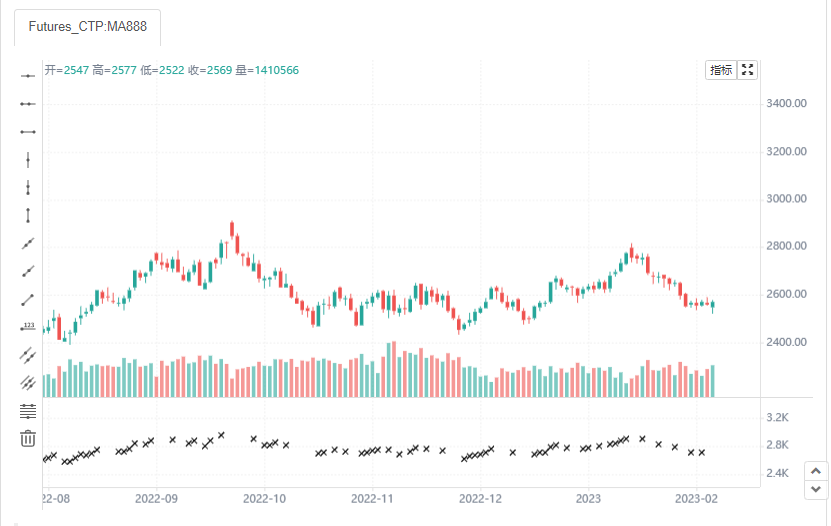
这里我们看到只显示收盘价大于开盘价时的乘号标志。
- title (const string) 绘图标题。
- style (input string) 绘图类型。可能的值有:shape.xcross(乘号),shape.cross(加号),shape.triangleup(上三角),shape.triangledown(下三角),shape.flag(旗帜),shape.circle(圆圈),shape.arrowup(上箭头),shape.arrowdown(下箭头),shape.labelup(上升标签),shape.labeldown(下降标签),shape.square(方块),shape.diamond(菱形)。 默认值为shape.xcross。同样,这里也可以使用三元表达式的形式,对不同条件选择不同的图案。
plotshape(close, style=close > open ? shape.arrowup: shape.arrowdown)
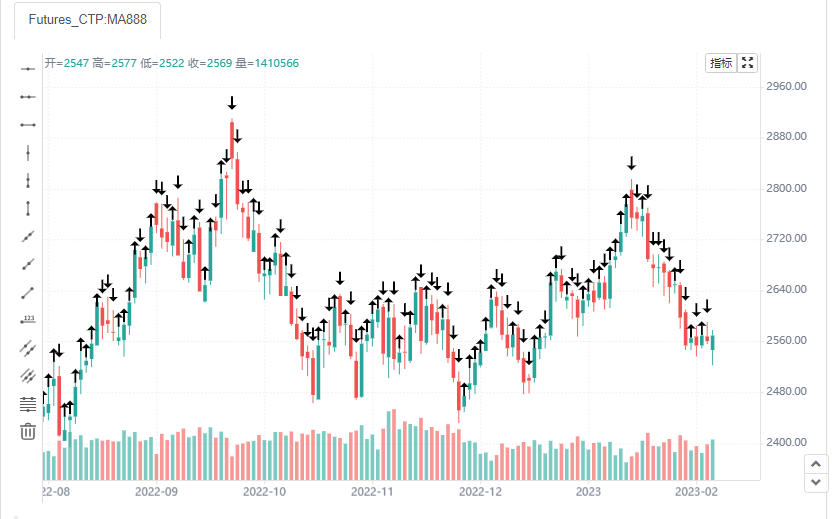
这里我们看到如果收盘价大于开盘价,使用上升箭头,否则使用下降箭头。
- location (input string) 形状在图表上的位置。 可能的值有:location.abovebar(k线上),location.belowbar(k线上),location.top(图表最上方),location.bottom(图表最下方),location.absolute(贴合k线)。 默认值为location.abovebar。同样的,可以使用三元表达式。
- color (series color) 形状的颜色。 可以使用如’color = color.red’或’color =#ff001a’的常量以及三元表达式复杂表达式。 可选参数。
- offset (series int) 在k线特定数量上向左或向右移动形状。 默认值为0。
- text (const string) 文字以形状显示。 您可以使用多行文本,分隔行使用’\n’转义序列。示例:’line one\nline two’。同样可以使用三元表达式。
plotshape(close, style=close > open ? shape.arrowup: shape.arrowdown, text = close > open ? '涨': '跌', textcolor = close > open ? color.red: color.green)
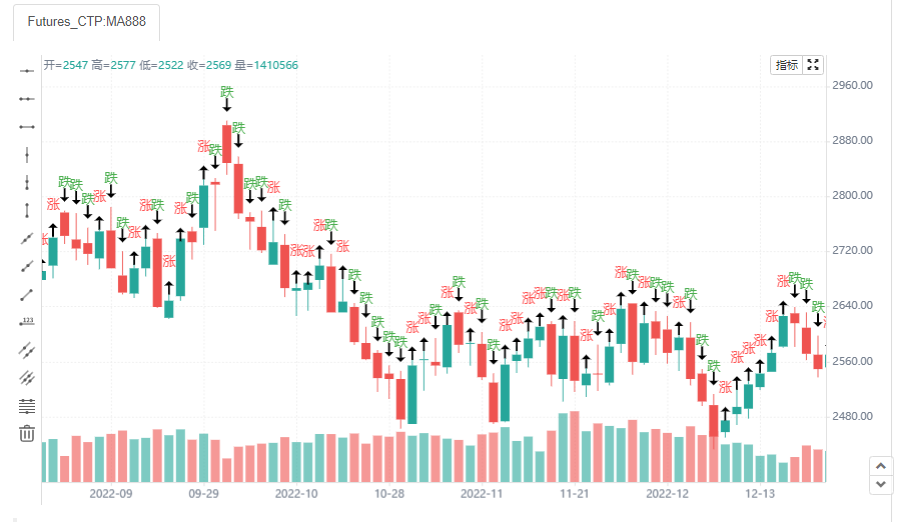
- textcolor (series color) 文字的颜色。 和上方的颜色设置一样。
- size (const string) 图表上字符的大小。 可能的值有: size.auto, size.tiny, size.small, size.normal, size.large, size.huge。默认值为size.auto。同样可以使用三元表达式。
plotchar
该函数在图表上使用任何给定的Unicode字符绘制可视形状。
plotchar(series, title, char, location, color, offset, text, textcolor, editable, size, show_last, display)
重要的参数和上述讲解的基本一致:
- series (series bool) 作为形状绘制的一系列数据。 除了location.absolute之外,系列被视为所有位置值的一系列布尔值。 必要参数。
- title (const string) 绘图标题。
- char (input string) 作为视觉形状使用的字符
- location (input string) 形状在图表上的位置。 可能的值有:location.abovebar,location.belowbar,location.top,location.bottom,location.absolute。 默认值为location.abovebar。
- color (series color) 形状的颜色。 您可以使用如’color = red’或’color =#ff001a’的常量以及如 ‘color = close >= open ? green : red’的复杂表达式。 可选参数。
- offset (series int) 在k线特定数量上向左或向右移动形状。 默认值为0。
- text (const string) 文字以形状显示。 您可以使用多行文本,分隔行使用’\n’转义序列。示例:’line one\nline two’。
- textcolor (series color) 文字的颜色。 您可以使用如 ‘textcolor=red’ 或’textcolor=#ff001a’ 的常量,以及如’textcolor = close >= open ? green : red’的复杂表达式。 可选参数。
- size (const string) 图表上字符的大小。 可能值有:size.auto,size.tiny,size.small,size.normal,size.large,size.huge。 默认值为size.auto。
plotchar有很多灵活的运用,比如在k线图中标注“十字星”。十字星是一种趋势信号判断的一个重要指标,十字星出现说明多空双方争夺激烈,互不相让。其基本定义为如果一日内开盘价和收盘价的差距很少,或者相等。因此,代码中使用数学绝对值(math.abs)的形式判断开盘价和收盘价的差距,如果差距小于等于5,则定义为十字星出现,判断为true。然后使用plotchar在图表中展示。
data = math.abs(close - open) <=5
plotchar(data, char='十字星')
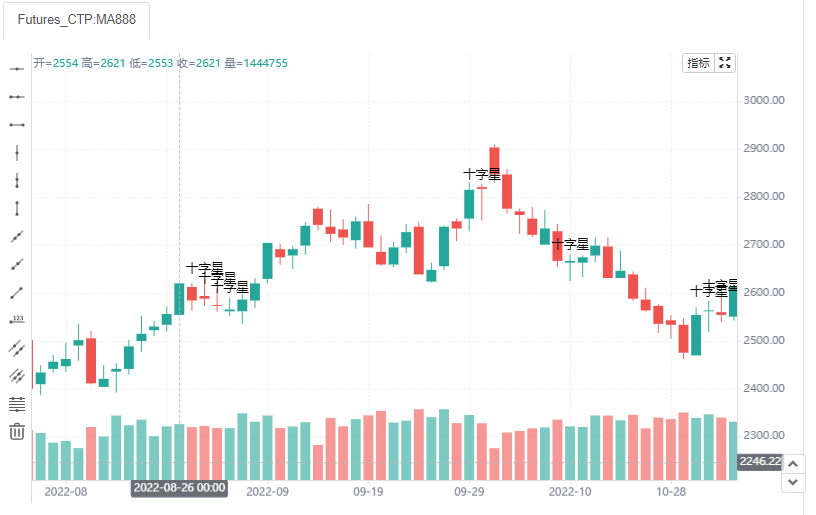
plotcandle
在图表上绘制蜡烛。
plotcandle(open, high, low, close, title, color, wickcolor, editable, show_last, bordercolor, display)
例子
indicator("plotcandle example", overlay=true)
plotcandle(open, high, low, close, title='Title', color = open < close ? color.green : color.red, wickcolor=color.black)
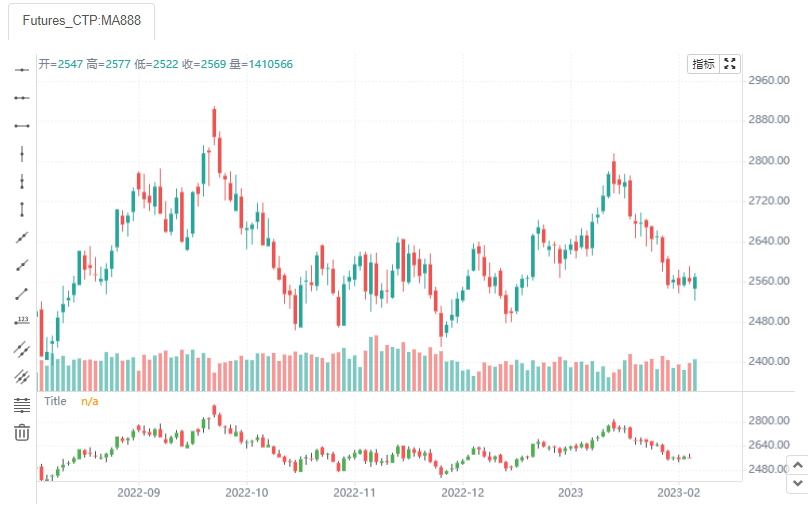
其重要的参数如下所示:
- open (series int/float) 数据开放系列用作蜡烛开盘值。必要参数。
- high (series int/float) 高系列数据用作蜡烛的高值。必要参数。
- low (series int/float) 低系列数据被用作蜡烛的低值。 必要参数。
- close (series int/float) 关闭系列数据作为关闭k线的值。 必要参数。
- wickcolor (series color) 蜡烛灯芯的颜色。一个可选参数。
plotarrow
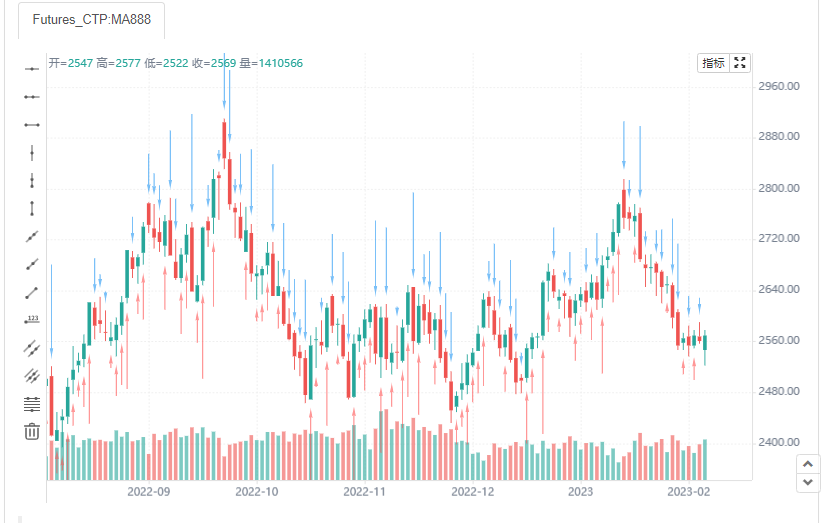
在图表上绘制向上和向下箭头:向上箭头绘制在每个正值指标上,而向下箭头绘制在每个负值上。 如果指标返回na,则不会绘制箭头。 箭头具有不同的高度,指标的绝对值越大,绘制箭头越长。
plotarrow(series, title, colorup, colordown, offset, minheight, maxheight, editable, show_last, display)
codiff = close - open
plotarrow(codiff, colorup=color.new(color.teal,40), colordown=color.new(color.orange, 40), overlay=true)
其重要参数如下所示,其他参数按照默认值即可:
series (series int/float) 要绘制成箭头的数据系列。 必要参数。
colorup (series color) 向上箭头的颜色。可选参数。
colordown (series color) 向下箭头的颜色。可选参数。
offset (series int) 在K线特定数量上向左或向右移动箭头。 默认值为0。
minheight (input int) 以像素为单位最小可能的箭头高度。默认值为5。
maxheight (input int) 以像素为单位的最大可能的箭头高度。默认值为100
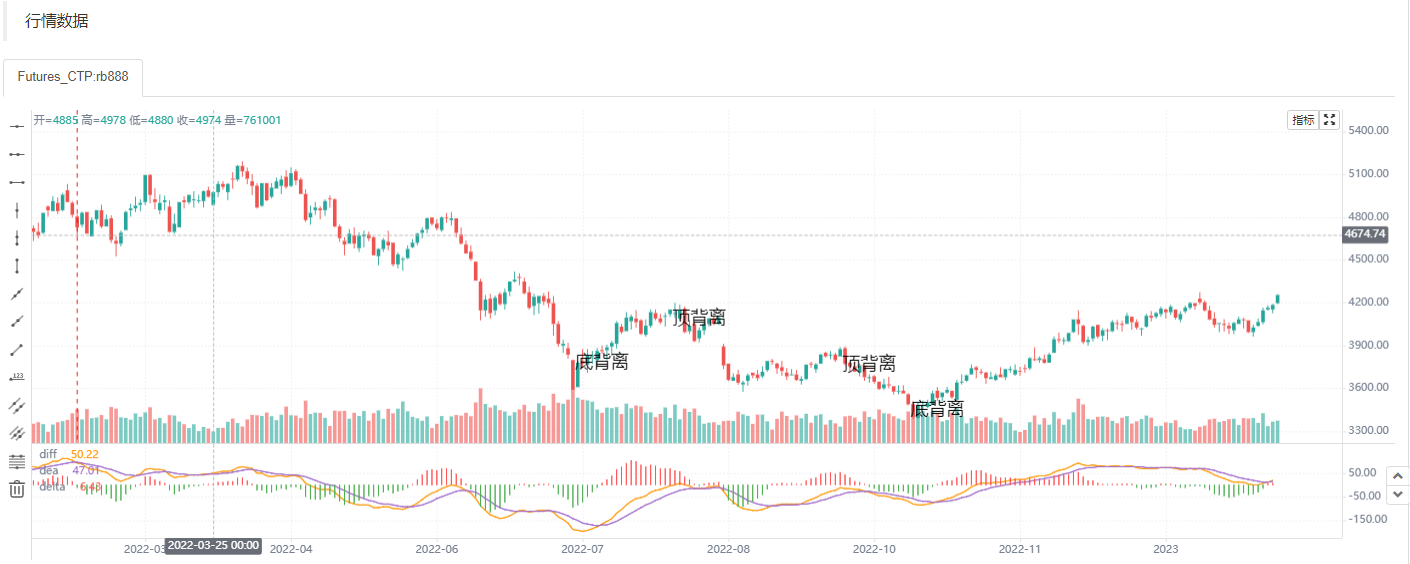
顶/底背离指标观察系统
顶背离:K线图上的价格走势一峰比一峰高,价格一直在向上涨,而MACD指标图形上的由红柱构成的图形的走势是一峰比一峰低,即当价格的高点比前一次的高点高、而MACD指标的高点比指标的前一次高点低,这叫顶背离现象。这是一个有“多”转“空”的参考信号。 底背离:K线图上的价格走势一峰比一峰低,价格一直在向下跌,而MACD指标图形上的由绿构成的图形的走势是一峰比一峰高,即当价格的低点比前一次的低点低、而MACD指标的低点比指标的前一次低点高,这叫底背离现象。这是一个有“空”转“多”的参考信号。
MACD指标
12日EMA的计算:EMA12 = 前一日EMA12 * 11⁄13 + 今日收盘 * 2⁄13 26日EMA的计算:EMA26 = 前一日EMA26 * 25⁄27 + 今日收盘 * 2⁄27 差离值(DIF)的计算: DIF = EMA12 - EMA26 9日DEA = 前一日DEA * 8⁄10 + 今日DIF * 2/10BAR=(DIF-DEA)*2 MACD=(DIF-DEA)*2
fastline = ta.ema(close,12)
slowline = ta.ema(close,26)
diff = fastline - slowline
dea = ta.ema(diff,9)
macd = 2*(diff - dea)
顶背离:
快线下穿慢线: MACD 从正转为负(下穿0线) 价格逐渐上涨:今日价格大于昨日
bot_diver = ta.crossunder(macd,0) and close[1] < close
plotchar(top_diver, char='顶背离', location = location.abovebar, size = size.normal, overlay=true)
底背离:
快线上穿慢线: MACD 从负转为正(上穿0线) 价格逐渐上跌:今日价格小于昨日
bot_diver = ta.crossover(macd,0) and close[1] > close
plotchar(bot_diver, char='底背离', location = location.belowbar, size = size.normal, overlay=true)
(十三):自定义函数和内置变量
大家好,今天我们来学习Pine语言“量化策略弹药组装”的载体–函数。基本上所有信号指标的计算和交易逻辑的判断,使用的都是函数。在Pine语言中,函数的使用贯彻了一贯的简洁优雅的特点。通过准确的使用各个逻辑代码块,可以实现量化策略的“所写即所得”。如果你想偷懒,不想重复的编写成熟的指标计算的轮子,例如MACD,布林带,超级趋势等指标,Pine的内置变量和内置函数一行代码就可以帮你搞定。
自定义函数
Pine语言可以设计自定义函数,首先需要设置函数的名称,和以前的变量命名的规范是一样的;名称过后需要添加一个“()”,里面可以添加需要的参数个数,当然0个也是可以的;“()”后面添加一个箭头“=>”标志;最后书写本地代码块,定义函数的返回内容。
一般来说Pine语言的自定义函数有以下规则:
- 1. 所有函数都在脚本的全局范围内定义。不能在另一个函数中声明一个函数,当然可以在另一个函数中使用一个函数。
- 2. 不允许函数在自己的代码中调用自己(递归)。
- 3. 函数主要是用来编写逻辑策略的,原则上所有PINE语言内置画图函数,不能在自定义函数内调用。
- 4. 函数可以写成单行、多行。最后一条语句的返回值为当前函数返回值,返回值可以返回元组形式。
单行自定义函数:
barIsUp() => close > open
该函数返回当前BAR是否为阳线。这里如果要打印该函数的话,需要引用的方式如下,这里不能省略括号。
runtime.log(barIsUp())
多行自定义函数
自定义函数也可以设计成多行的自定义函数,本地块语句需要以四个空格或者一个tab键换行;伴随下一个逻辑块,继续进行标准缩进。
该函数的意思是计算所需交易指标(data)的指定期间(length)的平均数。在函数体内,设置本地变量(i和sum),然后伴随while的循环,本地变量不断更新,直至循环结束,返回平均数(sum / length)。
sma(data, length) =>
i = 0
sum = 0
while i < 10
sum += data[i]
i += 1
sum / length
还有,也可以实现多变量的返回,使用一个元祖“[]”就可以。
twoEMA(data, fastPeriod, slowPeriod) =>
fast = ta.ema(data, fastPeriod)
slow = ta.ema(data, slowPeriod)
[fast, slow]
请注意,这里自定义函数内部,使用了一个内置函数(ta.ema),下部分我将为大家讲解。
这个函数通过三个参数(交易指标,快线周期,慢线周期),最后返回的是每个策略周期内,快线和慢线的平均数,以元组的形式。
内置变量
在介绍内置函数之前,我先为大家介绍一下Pine语言中的内置变量,这类变量不需要使用函数的形式,即不用添加参数,可以直接使用。内置变量数目有很多,在以往的课程中某些会涉及到,在这里为大家查漏补缺下,挑选一下重要的内置变量为大家讲解下。
指标计算类
指标计算类是量化策略中的常用的计算指标,Pine语言对此实现了封装,大家可以直接使用。
数学指标类
math.e
//是欧拉数的命名常数。它等于2.7182818284590452。
math.phi
//是黄金分割的命名常数。等于1.6180339887498948。
math.pi
//是阿基米德常数的命名常数。它等于3.1415926535897932。
math.rphi
//是黄金分割率的命名常数。它等于0.6180339887498948。
简单指标类
Pine语言对关键词赋予了交易指标的函数,可以直接调用计算,并且简单的合成指标也可以直接引用。
close
open
high
low
volume
hl2 //(最高价 + 最低价)/2的快捷键
hlc3 //(最高价+最低价+收盘价)/3的快捷键
hlcc4 //(高+低+收+收)/4的快捷键
ohlc4 //(开盘价 + 最高价 + 最低价 + 收盘价)/4的快捷键
复杂指标类
量化策略中,具有很多成熟的指标,然而计算公式比较复杂,在Pine语言中实现了直接调用。请注意,这类指标是不需要参数的,如有需要参数,可以参考内置函数内容,我们后续会为大家讲述。
ta.accdist
累积/分布指数
ta.iii
盘中强度指数
ta.nvi
负量指标。
ta.pvi
正量指标
ta.obv
能量潮指标
ta.pvt
价量趋势指标
ta.wad
威廉多空力度线
ta.wvad
威廉变异离散量
这类变量都可以使用自定义函数进行计算,比如最后威廉变异离散量,使用的自定义函数如下:
plot(ta.wvad, title = '内置wvad', color=color.yellow)
f_wvad() =>
(close - open) / (high - low) * volume
plot(f_wvad(), title = '自定义wvad')
时间序列类
时间序列类变量是确定策略执行的时间或者查询bar状态。
bar_index
//目前的价格棒指数。 编号从零开始,第一个条的索引为0。
last_bar_index
//最后一根图表K线的索引。K线索引以第一根K线为零开始。请注意,使用此变量可能会导致指标重绘。
time
//UNIX格式的当前k线时间。 这是自1970年1月1日00:00:00 UTC以来的毫秒数。
year
//交易所时区的当前年份
month
//交易所时区的当前月数
hour
//交易所时区的当前小时数
minute
//交易所时区的当前分钟数
weekofyear
//交易所时区的当前k线时段的周数
dayofmonth
//交易所时区的当前k线时间的日期
dayofweek
//交易所时区的当前k线时间的星期
barstate.ishistory
//如果当前k线为历史k线,则返回true,否则返回false。
barstate.isnew
//如果脚本目前在新k线上计算着,则返回true,否则返回false。使用此变量的PineScript代码可以对历史记录和实时数据进行不同的计算。请注意,使用此变量/函数可能会导致指标重新绘制。
这些内置变量主要是限制策略执行的时间,比如在早上开盘前十五分钟小时内,大盘波动比较剧烈,匆忙的进行开平仓操作可能造成不必要的损失。例如可用以下限制,在早上9点前十五分钟内(hour == 9 and minute <= 15),不进行策略运行。具体的代码设置如下:
if not (hour == 9 and minute <= 15)
runtime.log('策略开始')
Pine语言还有一些其他内置变量,我们没有讲解到。大家可以在优宽社区Pine语言帮助文档查询其他内置变量的功能和使用方法。
(十四):内置函数:math.系列和ta.系列
大家好,在上节课的自定义函数课程中,我们进行的都是简单的逻辑判断或者指标的计算,然而通常情况下,在实际的量化测量策略中,我们通常需要多个成熟的指标进行综合应用和逻辑比较。因此,在策略函数中可以使用成熟的内置函数,可以避免代码的臃肿,减轻我们的工作量。
内置函数
Pine语言内置函数分类有以下几种:
- 1、字符串处理函数str.系列。
- 2、颜色值处理函数color.系列。
- 3、参数输入函数input.系列。
- 4、指标计算函数ta.系列。
- 5、画图函数plot.系列。
- 6、数组处理函数array.系列。
- 7、交易相关函数strategy.系列。
- 8、数学运算相关函数math.系列。
- 9、其它函数(时间处理、非plot系列画图函数、request.系列函数、类型处理函数等)。
可以看到,内置函数确实有很多类,如果你想实现一个函数功能,但是又不想重复造轮子,你可以很方便地在优宽社区帮助文档中查询。在这其中,color.系列,input.系列,和plot.系列我们在以前的课程都讲述过。本节课的内容,我将集中于数学运算相关函数math.系列和指标计算函数ta.系列内置函数的讲解。
math.系列内置函数
math.系列内置函数涉及到对交易指标的原始计算,基本上所有基础的对于数字和集合的处理,math系列函数都可以满足。如果你觉得成熟的指标过于老旧,喜欢挑战原创交易指标的同学,你一定不要错过。
math系列内置函数有很多,因此我进行了分类帮助大家更方便的记忆。
基本上可以分为三类,第一种处理单个数字,比如取整,取不同对数,或者获得数字符号等:
- math.abs(number) 绝对值
- math.ceil(number) 大于等于取整整数
- math.floor(number) 小于等于取整整数
- math.round(number) 四舍五入到最接近的整数; 如果使用了 precision 参数,则返回一个四舍五入到小数位数的浮点值
- math.exp(number) e的number次方
- math.log(number) 自然对数
- math.log10(number) 以10为底的对数
- math.pow(base, exponent) 数学幂函数
- math.sign(number) >0: 1; =0: 0; : -1
- math.sqrt(number) 平方根
runtime.log('绝对值',math.abs(-5)) // 5
runtime.log('⼤于等于取整',math.ceil(3.14)) //4
runtime.log('⼩于等于取整',math.floor(3.14)) //3
runtime.log('四舍五⼊',math.round(3.14,precision= 1) ) //3.1
runtime.log('e的number次⽅ ',math.exp(1)) //2.718281828459045
runtime.log('⾃然对数',math.log(math.e)) //1
runtime.log('以10为底的对数 ',math.log10(10)) //1
runtime.log('数学幂函数 ',math.pow(math.e, 1)) //2.718281828459045
runtime.log('符号',math.sign(-5) ) //-1
runtime.log('开方',math.sqrt(9) ) //3
第二种处理角度,根据三角函数,获得不同角度对应值。
- math.acos() 数字的反余弦
- math.asin() 反正弦
- math.atan() 反正切
- math.cos() 余弦
- math.sin() 正弦
- math.tan() 三角正切
- math.todegrees(radians) 返回以度为单位的近似等效角度
- math.toradians(degrees) 返回以弧度为单位的近似等效角度
math.sin(math.pi/6) // 0.4999
math.asin(0.5) // 0.52 = math.pi/6
math.todegrees(math.pi)// 180
第三种处理数据集合,比如取最大值,最小值和随机数等,这部分的内容会和array函数有些重合,我们后续会为大家讲解。
- math.max(number0, number1, …) 返回多个值中最大值
- math.min(number0, number1, …) 最小值
- math.avg(number0, number1, …) 平均值
- math.sum(source, length) 返回x的最后y值的滑动综合
- math.random(min, max, seed) 返回伪随机值
math.max(1, 2, 3, 4, 5) //5
math.min(1, 2, 3, 4, 5) //1
math.avg(1, 2, 3, 4, 5) //3
math.sum(close, 3) //以3为周期的close滑动综合值
math.random(1, 5, 2) // 设定最小值为1,最大值为5,seed为2,每次随机返回值都一致
ta.系列内置函数
TA,全称“Technical Analysis”, 即技术分析指标,是Pine语言封装的金融量化的高级库,涵盖了50多种股票、期货交易软件中常用的技术分析指标,如 MACD、RSI、KDJ、动量指标、布林带等等。下面我为大家初步介绍下。
经过整理,ta.系列内置函数可分为以下子板块:
均线处理函数
研究发现,资产的长期价格呈现均值回复的特征,即从长期来看,资产的价格会回归均值。这也是均线理论被广泛应用的前提。因此,在量化指标中,方便的均线处理内置函数必不可少。
- ta.alma(series, length, offset, sigma, floor) Arnaud Legoux移动平均线。它使用高斯分布作为移动平均值的权重。 series (series int/float) 待执行的系列值。 length (series int) K线数量(长度). offset (simple int/float) 控制平滑度(更接近1)和响应性(更接近0)之间的权衡。 sigma (simple int/float) 改变ALMA的平滑度。Sigma越大,ALMA越平滑。 floor (simple bool) 可选参数。在计算ALMA之前,指定偏移量计算是否为下限。默认值为false。
- ta.sma(source, length) 移动平均值
- ta.ema(source, length) 指数加权移动平均线
- ta.wma(source, length) 返回length K线的 source 的加权移动平均值
- ta.swma(source) 具有固定长度的对称加权�
- 3/4阴量线:从交易灵感到量化实践——商品期货实战探秘
- 奏响市场乐章:量化视角解析谐波形态
- 基于量化指标的蜡烛情绪动量趋势交易策略
- 期货行情引爆的导火线?量价关系的量化研究
- 商品期货“横久必跌”现象的量化实证研究
- 网红指标RSRS在商品期货中的应用
- 浅谈如何区分趋势和震荡行情:实战方法与代码详解
- 如何从学术论文中获取策略灵感:隔夜反转策略实现
- 量化揭秘纯碱2023年操盘手法:157倍的快乐你想象不到
- 智能数据驱动量化策略:基于聪明钱的日内交易模型
- 商品期货价格数据的降噪处理:以傅立叶变换和卡尔曼滤波变换为例
- 国庆礼包:穿越牛熊市!网格交易策略揭秘与收益实战
- 深度解析商品期货中的胜率与盈亏比:交易策略成败的关键
- 商品期货风险控制:一个函数挽救400W的损失
- 优宽量化平台与CTP系统接口的深度融合及应用指南
- 商品期货「订单流」系列文章(四):微单和POC
- 探索优宽量化:状态栏按钮的全新应用(一)
- 商品期货「订单流」系列文章(三):供需失衡和堆积带
- 详解优宽量化交易平台API升级:提升策略设计体验
- 商品期货「订单流」系列文章(二):Delta指标