机器学习(一):聚类分析在商品期货市场中的应用
 0
807
0
807

一、聚类分析的概念
大家好!今天我们要聊聊一种超级有趣的分析方法——聚类分析!它就像一个魔法师,能把一堆看似杂乱无章的数据,变出有规律可循的类别或簇,让我们更容易理解和预测它们的走势。
二、如何进行聚类分析
首先,我们需要收集和整理期货品种的收盘价数据。然后,进行以下步骤: 确定目标品种:我们挑选的目标品种都是比较活跃的品种,一共有44个。
| 商品名称 | 代码 | 交易所代码 | 交易所 |
|---|---|---|---|
| 黄大豆2号 | b | DCE | 大商所 |
| 聚丙烯 | pp | DCE | 大商所 |
| 聚氯乙烯 | v | DCE | 大商所 |
| 豆粕 | m | DCE | 大商所 |
| 铁矿石 | i | DCE | 大商所 |
| 棕榈油 | p | DCE | 大商所 |
| 黄大豆1号 | a | DCE | 大商所 |
| 焦煤 | jm | DCE | 大商所 |
| 黄玉米 | c | DCE | 大商所 |
| 玉米淀粉 | cs | DCE | 大商所 |
| 豆油 | y | DCE | 大商所 |
| 冶金焦炭 | j | DCE | 大商所 |
| 苯乙烯 | eb | DCE | 大商所 |
| 液化石油气 | pg | DCE | 大商所 |
| 生猪 | lh | DCE | 大商所 |
| 鲜鸡蛋 | jd | DCE | 大商所 |
| 乙二醇 | eg | DCE | 大商所 |
| 线型低密度聚乙烯 | l | DCE | 大商所 |
| 原油 | sc | INE | 上能源 |
| 低硫燃料油 | lu | INE | 上能源 |
| 国际铜 | bc | INE | 上能源 |
| 铜 | cu | SHFE | 上期所 |
| 不锈钢 | ss | SHFE | 上期所 |
| 石油沥青 | bu | SHFE | 上期所 |
| 锡 | sn | SHFE | 上期所 |
| 锌 | zn | SHFE | 上期所 |
| 铅 | pb | SHFE | 上期所 |
| 热轧卷板 | hc | SHFE | 上期所 |
| 燃料油 | fu | SHFE | 上期所 |
| 白银 | ag | SHFE | 上期所 |
| 铝 | al | SHFE | 上期所 |
| 螺纹钢 | rb | SHFE | 上期所 |
| 黄金 | au | SHFE | 上期所 |
| 镍 | ni | SHFE | 上期所 |
| 天然橡胶 | ru | SHFE | 上期所 |
| 漂针浆 | sp | SHFE | 上期所 |
| 精对苯二甲酸 | TA | CZCE | 郑商所 |
| 甲醇 | MA | CZCE | 郑商所 |
| 硅铁 | SF | CZCE | 郑商所 |
| 玻璃 | FG | CZCE | 郑商所 |
| 尿素 | UR | CZCE | 郑商所 |
| 白砂糖 | SR | CZCE | 郑商所 |
| 锰硅 | SM | CZCE | 郑商所 |
| 纯碱 | SA | CZCE | 郑商所 |
收集数据:这里可以借用我们优宽的本地回测工具。创建一个dataframe保存我们的k线数据。
'''backtest
start: 2023-01-03 09:00:00
end: 2023-11-01 15:00:00
period: 1d
basePeriod: 1h
exchanges: [{"eid":"Futures_CTP","currency":"FUTURES","depthDeep":20}]
'''
from youquant import *
task = VCtx(__doc__)
dataDf = pd.DataFrame(columns=["InstrumentId", "Instrument", "Time", "Close"])
for i in range(len(df["代码"])):
rlist = []
rlisttime = []
prebartime = 0
mainId = df["代码"][i] + '888'
print(mainId)
codeId = df["商品名称"][i]
while True:
try:
exchange.SetContractType(mainId)
r = exchange.GetRecords(PERIOD_D1)
if r[-1].Time != prebartime:
for j in range(len(r) - 1):
if r[j].Time not in rlisttime:
rlist.append([mainId, codeId, r[j].Time, r[j].Close])
rlisttime.append(r[j].Time)
prebartime = r[-1].Time
else:
continue
new_rows = pd.DataFrame(rlist, columns=["InstrumentId", "Instrument", "Time", "Close"])
dataDf = dataDf.append(new_rows, ignore_index=True)
except Exception as e:
print(mainId + '数据读取完成')
break
数据预处理:把收到的数据清洗、整理一下,让它们更标准。因为各个品种的价格不是一致的,所以我们决定使用涨跌幅作为特征,让它们标准化。
pivoted_data = dataDf.pivot_table(index='Time', columns='Instrument', values='Close', aggfunc='mean')
# 计算每个仪器的涨跌幅
returns = pivoted_data.pct_change()
# 删除第一行,因为第一行的涨跌幅无法计算
returns = returns.iloc[1:]
returns = returns.T
聚类分析:接种我们使用两种聚类方法,进行K-means和层次聚类,将期货品种分成若干个簇。每个簇就像一个大家庭,里面的成员都长得比较像。
- K-means聚类
当我们谈论K-means聚类时,实际上是在讨论一种将数据分成几组的方法。这种方法的思路是,首先假设我们要将数据分成K组,然后随机选择K个点作为这些组的中心。接下来,我们将其他的数据点分配到离它最近的中心所代表的组里面。然后,计算每个组的平均值,并将这些平均值作为新的中心。接着,重复这个过程直到中心不再发生变化或者达到设定的迭代次数为止。
简单来说,K-means聚类就像是把一堆东西分成几组的游戏。我们先猜测一下,选出几个代表这些组的点,然后把其他的东西分别放到离它们最近的组里面。接着,重新计算每个组的中心,重新分组,直到达到我们认为合适的结果为止。
这种方法通常用于寻找数据中隐藏的结构,例如,如果我们有很多个数据点,但是不知道它们应该被分成哪些类别,K-means可以帮助我们找到一种合理的分组方式。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.font_manager
matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf')
# 设置中文字体为SimHei或者Microsoft YaHei
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 假设你的数据框为returns,包含了每日涨跌幅数据
# K-Means 聚类
n_clusters = 3 # 选择簇的数量
kmeans = KMeans(n_clusters=n_clusters)
kmeans.fit(returns)
returns['KMeansCluster'] = kmeans.labels_
clustered_indices = returns.groupby('KMeansCluster').apply(lambda x: x.index.tolist())
print(clustered_indices[0])
print(clustered_indices[1])
print(clustered_indices[2])
K-means聚类图表显示结果较差,所以我们直接打印每一个簇包含的种类。
['乙二醇', '冶金焦炭', '尿素', '热轧卷板', '焦煤', '玻璃', '甲醇', '硅铁', '纯碱', '线型低密度聚乙烯', '聚丙烯', '聚氯乙烯', '螺纹钢', '铁矿石', '锰硅']
['低硫燃料油', '原油', '液化石油气', '燃料油', '石油沥青', '精对苯二甲酸', '苯乙烯']
['不锈钢', '国际铜', '天然橡胶', '棕榈油', '漂针浆', '玉米淀粉', '生猪', '白砂糖', '白银', '豆油', '豆粕', '铅', '铜', '铝', '锌', '锡', '镍', '鲜鸡蛋', '黄大豆1号', '黄大豆2号', '黄玉米', '黄金']
这些商品可以被归为几个类别:
第一组:化工原料(如乙二醇、尿素、甲醇等)、黑色系(如螺纹钢、热轧卷板等); 第二组:能源类商品(如原油、燃料油等); 第三组:贵金属以及农副产品(如玉米淀粉、豆油、生猪等)
在第一个类别中,我们可以看到黑色系和化工原料的集合,因为这些商品在生产过程中通常会用到。第二个类别是一些石油和能源相关的商品,这也是合理的归类。最后一个类别包含了农产品和金属商品,这些商品可能在投资和商品交易中具有相似的特性的。
- 层次聚类
层次聚类就像是搭积木一样,它会根据每个数据点之间的相似度,逐步把它们合并成不同的群组。首先,每个数据点都被视为一个单独的群组。然后,算法会找到最相似的两个群组,把它们合并成一个新的群组。接着,重复这个过程,不断地将更相似的群组合并起来,直到所有的数据点都被归为一个大的群组为止。
这种方法有点像是从小到大慢慢地把东西合并起来,最终形成一个层次化的分类结构,就像是树枝和树干一样,由小的部分逐渐合并成大的部分。层次聚类的结果可以用树状图来展示数据之间的关系,帮助我们更直观地理解数据的内在结构。
# 进行层次聚类
linked = linkage(returns, method='ward')
# 绘制层次聚类树状图
plt.figure(figsize=(20, 16))
dendrogram(linked, orientation='top', distance_sort='descending', labels=returns.index)
plt.title('Hierarchical Clustering Dendrogram')
plt.tick_params(axis='x', labelsize=12)
plt.show()
# 获取每一个聚类对应的索引
from scipy.cluster.hierarchy import fcluster
n_clusters = 3 # 假设选择3个簇
clusters = fcluster(linked, n_clusters, criterion='maxclust')
cluster_indices = {}
for i in range(1, n_clusters+1):
cluster_indices[i] = returns.index[clusters == i].tolist()
print(cluster_indices)
这里我们可以进行图像展示。
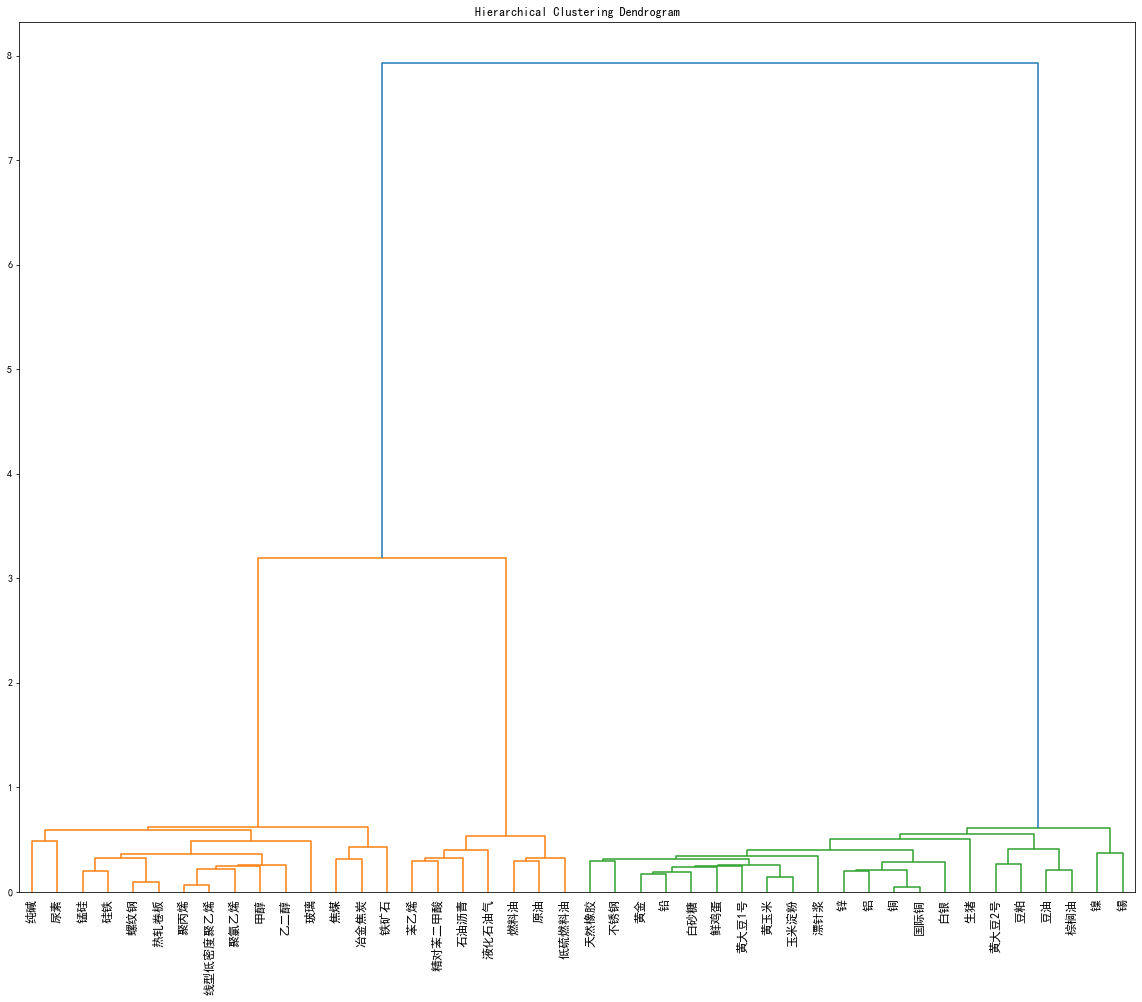
{1: ['不锈钢', '国际铜', '天然橡胶', '棕榈油', '漂针浆', '玉米淀粉', '生猪', '白砂糖', '白银', '豆油', '豆粕', '铅', '铜', '铝', '锌', '锡', '镍', '鲜鸡蛋', '黄大豆1号', '黄大豆2号', '黄玉米', '黄金'],
2: ['低硫燃料油', '原油', '液化石油气', '燃料油', '石油沥青', '精对苯二甲酸', '苯乙烯'],
3: ['乙二醇', '冶金焦炭', '尿素', '热轧卷板', '焦煤', '玻璃', '甲醇', '硅铁', '纯碱', '线型低密度聚乙烯', '聚丙烯', '聚氯乙烯', '螺纹钢', '铁矿石', '锰硅']}
第一组是农产品和贵金属的组合;第二组是原油系的组合,第三组是化工和黑色系的组合。
可以看到,两者聚类方法对于期货品种分类存在一致性,这可能表明这些期货品种之间在某种程度上存在着相似性或者相关性,使得它们被划分到了相同的类别中。
这种一致性结果可能有助于我们更好地理解期货市场的特点和商品之间的关联性。同时,也说明了无论采用何种聚类方法,都可以得出相对稳定和可靠的分类结果,这有助于我们在后续的分析和决策中更好地理解不同期货品种之间的联系和特性。
经过这次的尝试,我们发现聚类分析确实找出不同品种之间“派系”的区别。当然,我们的算法比较粗糙,大家在尝试聚类分析的过程中可以优化。通过聚类分析,我们可以更好地理解市场结构、发现投资机会并管理市场风险。同时,聚类分析还可以为我们的研究和分析提供有益的辅助工具。
本系列课程旨在为大家介绍机器学习技术在商品期货量化交易中的应用,其他相关文章请点击下面链接:
- 机器学习(四):商品期货多种回归算法的运用和比较
- 在优宽平台搭建多因子模型(三):Alphalens包的应用
- 机器学习(三):自相关模型在商品期货中的应用
- 风险平价(Risk Parity)理论及其在商品期货中的应用
- 仓鼠机器人商品期货策略
- 在优宽平台使用开源数据库获取期货外部数据
- 商品期货中PnL损益指标的应用
- 机器学习(二):商品期货中的VAR模型应用
- 浅谈期货人经过的几层认知
- 在优宽平台搭建多因子模型(二):展期收益率单因子模型
- 在优宽平台搭建多因子模型(一):多因子策略介绍
- 优宽股票模拟盘程序化交易策略:布林带多品种策略
- 商品期货量化交易实践系列课程
- 使用KLineChart函数让策略画图设计更加简单
- 一根k线的故事
- 浅谈K线处理的底层机制
- 以平均K线图(Heikin-Ashi)算法为例教你写优宽扩展指标库
- 量化策略马后炮:浅谈量化交易中的过拟合问题
- 让策略程序真正并发执行,给JavaScript策略增加系统底层多线程支持
- 牛刀小试:用Pine语言画出顶背离和底背离指标观察系统